
-> Hier kostenlos registrieren
Hallo,
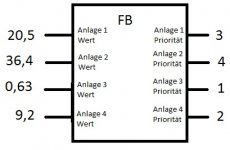
Ich muss ein FB erstellen an dem man an vier Eingängen vier REAL-Werte anlegen kann. Die vier Werte gehören jeweils zu einer Anlage.
Jetzt muss an 4 Ausgängen ein Integer-Wert ausgeben werden, der die Priorität ausgibt (1-4)
Umso kleiner die Zahl am Eingang desto höher die Priorität.
Beispiel
Eingang Ausgang
1 20,5 3
2 36,4 4
3 0,63 1
4 9,20 2
Gibt es da einen fertigen Baustein? Da ich nicht gut programmieren kann.
Vielen Dank für eure Hilfe
Ich muss ein FB erstellen an dem man an vier Eingängen vier REAL-Werte anlegen kann. Die vier Werte gehören jeweils zu einer Anlage.
Jetzt muss an 4 Ausgängen ein Integer-Wert ausgeben werden, der die Priorität ausgibt (1-4)
Umso kleiner die Zahl am Eingang desto höher die Priorität.
Beispiel
Eingang Ausgang
1 20,5 3
2 36,4 4
3 0,63 1
4 9,20 2
Gibt es da einen fertigen Baustein? Da ich nicht gut programmieren kann.
Vielen Dank für eure Hilfe

")


