vierlagig
Level-1
- Beiträge
- 9.882
- Reaktionspunkte
- 2.021
-> Hier kostenlos registrieren
...heut erst wieder 300 code-zeilen in den tiefen irgendeiner ablage verschwinden lassen, weil sie nicht zum ziel führten...
folgende konstellation:
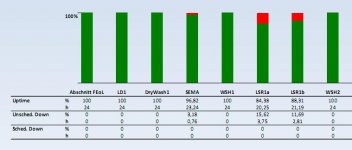
für ein "tool" kann einer von 14 status[²] gebucht werden. jeder status hat eine priorität. es wird die zeit und der buchende erfasst.
für ein tool wird dann ein zeitstrahl über einen bestimmten zeitraum mit den entsprechenden buchungen erstellt und ausgegeben, darüber hinaus werden die zeiten von status-gruppen zusammengefasst und daraus prozentuale werte zu "uptime", "utilization", "scheduledDown" und "unscheduledDown" berechnet.
soweit kein ding, das läuft primstens.
eine bestimmte anzahl von tools ergibt eine toolGruppe, einen linienabschnitt quasi. für die einzelnen linienabschnitte soll ebenfalls ein zeitstrahl erstellt und oben angesprochene auswertungen getätigt werden. klingt trivial, wenn der einfluss eines jeden tools 100% auf den linienabschnitt wären, aber es kann vorkommen, das tools parallel (bis zu 6) stehen und dementsprechend nur zu 50%, 40% (hier hat das handling seine finger im spiel, aber das ist egal, die werte sind gegeben) oder 16,6% in die gesamtwertung eingehen.
ich scheitere an der erstellung dieses timeTracks...
die buchungen überschneiden sich, logisch, und müssen entsprechend ihrer priorität in den resultierenden zeitstrahl eingehen. gleichzeitig muß aber auch der einfluss auf den teilabschnitt beachtet werden. also gibt es für einen zeitabschnitt x plötzlich zwei oder mehr buchungen unterschiedlicher priorität ...
wenn irgendjemand eine clevere idee zur erstellung dieser cluster hat, her damit ... meine kollegen befürchten, das mir bald das fluchvokabular ausgeht (...und nein, keiner von ihnen hat eine idee ) ... bin für jede sauerei zu haben... listen von arrays von structs mit arrays sind schon in der einfachen auswertung genug vorhanden, damit kann ich um
) ... bin für jede sauerei zu haben... listen von arrays von structs mit arrays sind schon in der einfachen auswertung genug vorhanden, damit kann ich um
geproggt wird übrigens in Craute mit dem punktNetzRahmenWerk 3.5, aber das ist IMHO irrelevant ...
² vgl.: http://de.wikipedia.org/wiki/Status
folgende konstellation:
für ein "tool" kann einer von 14 status[²] gebucht werden. jeder status hat eine priorität. es wird die zeit und der buchende erfasst.
für ein tool wird dann ein zeitstrahl über einen bestimmten zeitraum mit den entsprechenden buchungen erstellt und ausgegeben, darüber hinaus werden die zeiten von status-gruppen zusammengefasst und daraus prozentuale werte zu "uptime", "utilization", "scheduledDown" und "unscheduledDown" berechnet.
soweit kein ding, das läuft primstens.
eine bestimmte anzahl von tools ergibt eine toolGruppe, einen linienabschnitt quasi. für die einzelnen linienabschnitte soll ebenfalls ein zeitstrahl erstellt und oben angesprochene auswertungen getätigt werden. klingt trivial, wenn der einfluss eines jeden tools 100% auf den linienabschnitt wären, aber es kann vorkommen, das tools parallel (bis zu 6) stehen und dementsprechend nur zu 50%, 40% (hier hat das handling seine finger im spiel, aber das ist egal, die werte sind gegeben) oder 16,6% in die gesamtwertung eingehen.
ich scheitere an der erstellung dieses timeTracks...
die buchungen überschneiden sich, logisch, und müssen entsprechend ihrer priorität in den resultierenden zeitstrahl eingehen. gleichzeitig muß aber auch der einfluss auf den teilabschnitt beachtet werden. also gibt es für einen zeitabschnitt x plötzlich zwei oder mehr buchungen unterschiedlicher priorität ...
wenn irgendjemand eine clevere idee zur erstellung dieser cluster hat, her damit ... meine kollegen befürchten, das mir bald das fluchvokabular ausgeht (...und nein, keiner von ihnen hat eine idee
) ... bin für jede sauerei zu haben... listen von arrays von structs mit arrays sind schon in der einfachen auswertung genug vorhanden, damit kann ich umgeproggt wird übrigens in Craute mit dem punktNetzRahmenWerk 3.5, aber das ist IMHO irrelevant ...
² vgl.: http://de.wikipedia.org/wiki/Status
Zuletzt bearbeitet: