
BaumimGarten
Level-1
- Beiträge
- 63
- Reaktionspunkte
- 0
-> Hier kostenlos registrieren
Hallo Leute,
Ich bin gerade dabei ein JSON Telegram aus Zahlenwerten und Zeichen zusammen zusetzen und über MQTT zu verschicken. Bisher habe ich alle meine Werte und Zeichen in einen String umgeformt, um diese dann mit "concat" zusammenzufassen und anschließend in ein Char umgewandelt, um das Telegram für den MQTT Baustein lesbar zu machen.
Jedoch habe ich mittlerweile ein Problem, weil ein String ja nur eine Länge von max. 256 Zeichen hat und meine gesendeten Daten diese Länge überschreiten würde.
JSON Telegram als String sieht ungefähr so aus :
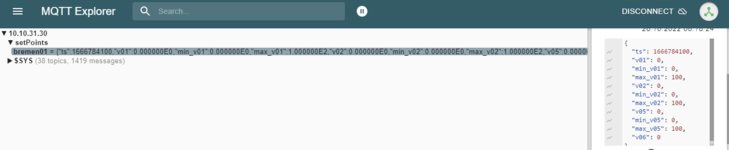
{"ts":166784105,"v01":0.000000E0,"min_v01":0.000000E0,"max_v01":0.000000E0,"v02":0.000000E0,"min_v02":0.000000E0,.......}
Um mein Problem zu lösen habe ich 2 Ansätze, jedoch weiß ich nicht welcher sinniger ist.
Meine Zahlenwerte bestehen aus Real zahlen, da ich ebenfalls Kommerzahlen anzeigen lassen muss. Hier könnte ich allerdings glaub ich einsparen, wenn ich eine Möglichkeit finde die Nachkommazahlen zu verringern, da ich maximal die zweite Stelle brauche. Wenn ich ein Real mit "Real_to_String umwandle, wird dieser immer mit "0.000000E0" angezeigt.
Alternative wäre, wenn ich einen anderen Weg finde meinen JSON nicht als String zusammenzufasse, sondern direkt als Char. Ich übergebe meinem MQTT Client im Endeffekt nur ein Array of Byte, weshalb ich da größeren Spielraum habe, als mit meinem 256 String. Ich könnte zwar mehrere Pakete in ein Array packen allerdings, hab ich das noch nie gemacht, aber es klingt für mich nach einer großen Fummelarbeit, um die Stelle zu finden wo dann das nächste Paket in das Array gesetzt werden muss.
Ich benutze eine S7 1200er mit TIA 16 und programmiere überwiegend in SCL
Vielleicht kann mir ja jemand dabei helfen
MfG Fabian
Ich bin gerade dabei ein JSON Telegram aus Zahlenwerten und Zeichen zusammen zusetzen und über MQTT zu verschicken. Bisher habe ich alle meine Werte und Zeichen in einen String umgeformt, um diese dann mit "concat" zusammenzufassen und anschließend in ein Char umgewandelt, um das Telegram für den MQTT Baustein lesbar zu machen.
Jedoch habe ich mittlerweile ein Problem, weil ein String ja nur eine Länge von max. 256 Zeichen hat und meine gesendeten Daten diese Länge überschreiten würde.
JSON Telegram als String sieht ungefähr so aus :
{"ts":166784105,"v01":0.000000E0,"min_v01":0.000000E0,"max_v01":0.000000E0,"v02":0.000000E0,"min_v02":0.000000E0,.......}
Um mein Problem zu lösen habe ich 2 Ansätze, jedoch weiß ich nicht welcher sinniger ist.
Meine Zahlenwerte bestehen aus Real zahlen, da ich ebenfalls Kommerzahlen anzeigen lassen muss. Hier könnte ich allerdings glaub ich einsparen, wenn ich eine Möglichkeit finde die Nachkommazahlen zu verringern, da ich maximal die zweite Stelle brauche. Wenn ich ein Real mit "Real_to_String umwandle, wird dieser immer mit "0.000000E0" angezeigt.
Alternative wäre, wenn ich einen anderen Weg finde meinen JSON nicht als String zusammenzufasse, sondern direkt als Char. Ich übergebe meinem MQTT Client im Endeffekt nur ein Array of Byte, weshalb ich da größeren Spielraum habe, als mit meinem 256 String. Ich könnte zwar mehrere Pakete in ein Array packen allerdings, hab ich das noch nie gemacht, aber es klingt für mich nach einer großen Fummelarbeit, um die Stelle zu finden wo dann das nächste Paket in das Array gesetzt werden muss.
Ich benutze eine S7 1200er mit TIA 16 und programmiere überwiegend in SCL
Vielleicht kann mir ja jemand dabei helfen
MfG Fabian




")