Ich bin mir nicht ganz sicher, was du genau machen willst, aber ich probier es mal.
Wenn ich dich richtig verstehe hast du frueher einen Index-DB gehabt. Da standen frueher die DB-Nummern der DB die Positionen enthalten drin und ein Hinweis darauf welche Positionen in den DBs drin sind. (Nummer der ersten und letzten Position)
Du hast frueher dann im Index DB eine Suche Anhand der gesuchten Postitionsnummer gemacht und die Suche hat dir die DB-Nummer ausgespuckt. Daraus hast du dir dann einen Any-Pointer gebastelt, mit dem auf den jeweiligen Positionen-DB zugegriffen und dort dann die gesuchte Position rausgesucht.
So hab ich das Verstanden.
Das Problem ist jetzt, das du dir in der neuen sauberen TIA-Welt keinen Any-Pointer basteln willst. Das ganze geht jetzt immernoch so, sogar einigermassen sicher, dass man nicht ausversehen im Nirvana landet und auch symbolisch. Man muss sich allerdings ein halbes Bein aussreissen, damit man da hin kommt wo man will.
Also, wenn du dir dieses Anwendungsbeispiel von Siemens anguckst zur Venwendung von DB_ANY machen die da was ganz aehliches, naemlich in einem DB mehrere Referenzen auf Datenbausteine in Form von DB_ANY ablegen und diese dann mit einem zwischengeschalteten Konvertierungsbaustein ihren Funktionsbausteinen von Technologieobjekten uebergeben.
https://cache.industry.siemens.com/...1861/v2/109750880_use_data_type_DB_ANY_de.pdf
Der unterschied ist, dass man DB_ANY wohl einfach als ein Technologyobjekt uebergeben kann, mit Global-DB geht das aber nicht so einfach.
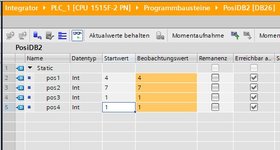
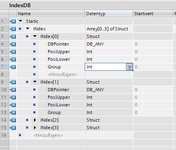
Der IndexDB besteht dazu aus einem Array of Stuct. In einem Arrayelement ist immer ein DB_ANY vorhanden, die untere und obere Positionsnummer und die Funktionsgruppe.
Das Array ist iterable und daher kannst du schonmal bequem mit For-Schleifen suchen. Mit LOWER/UPPER_BOUND sogar ohne projektspezifische Anpassungen.
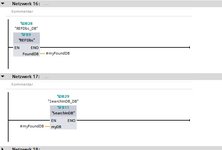
Initialisiert wird der IndexDB jetzt mit Zeigern auf die PositionsDBs, also ein Netzwerk mit Anweisungen in dem Stil:
"IndexDB".Index[0].DBPointer := "PosiDB1";
Der DBPointer ist vom Typ DB_ANY.
Der Suchbaustein iteriert nun ueber die Arrayeintraege, findet seinen Eintrag und kopiert den DBPointer in einen Ausgang FoundDB vom Typ DB_ANY.
Soweit die einfache Seite, frueher gab es halt DB-Nummern, die man in den IndexDB eingetragen hat, jetzt gibt es direkt Zeiger.
Die Seite mit den PositionsDB ist etwas komplizierter. Zuerst einmal muessen die vom richtigen Typ sein. Ein normaler globaler DB geht nicht, weil dem Compiler zur Uebersetzungszeit nicht bekannt ist, was in diesem steht, wenn ein Baustein nur den DB_ANY auf den Baustein uebergeben bekommt. Ab hier koenntest du halt mit Peek und Poke weitermachen wenn auf den PositionenDB nicht optimiert zugegriffen wird.
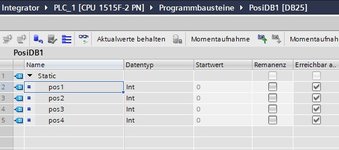
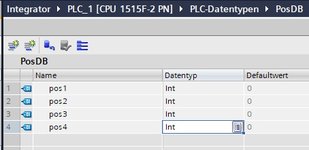
Stattdessen legst du einen UDT fuer diesen PositionsDB an, das kann ein Array of Int sein mit den Positionen drin oder irgendwas.
Mit dem geschaffenen UDT legst du jetzt einen DB an, also genauso wie bei einem Global-DB, nur dass du bei dem Erstellen des DB in dem Dropdown die UDT angibst statt "Global-DB".
Das machst du fuer alle PositionsDBs, immer mit dem gleichen UDT.
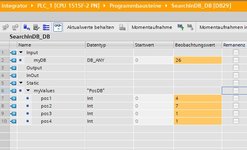
Der Baustein, der nun in dem PositionsDB suchen soll, bekommt jetzt den FoundDB von vorhin uebergeben, und wandelt diesen in einen Variant um. Das geht nicht mit einem Global-DB, daher der Aufwand mit dem UDT-DB.
#myVariant := DB_ANY_TO_VARIANT(in := #myDB, err => #dump);
Sollte dabei die Anweisung Fehler 8155 zurueckgeben liegt das daran, dass Siemens ein kleines Ei gelegt hat. Einfach so vorgehen wie in der Hilfe von DB_ANY_TO_VARIANT:
DB_ANY_TO_VARIANT: DB_ANY in VARIANT konvertieren (S7-1200, S7-1500)
1) Die Ursache für die Ausgabe des Fehlercodes #8155 liegt darin:
Es wurde ein PLC-Datentyp (UDT1) deklariert und anschließend ein Datenbaustein (DB2) vom Datentyp "UDT1" erstellt. In der Variablentabelle gibt es eine Variable (3) vom Datentyp DB_ANY. In einem Programmbaustein (4) wurde anschließend die Anweisung "DB_ANY_TO_VARIANT" aufgerufen und am Parameter IN mit der Variable (3) versorgt. Beim Ausführen liefert die Anweisung "DB_ANY_TO_VARIANT" den Fehlercode 16#8155.
Zur Auflösung des Fehlercodes gehen Sie folgendermaßen vor:
- Legen Sie eine Funktion (FC5) an und deklarieren Sie an der InOut-Schnittstelle eine Variable vom Datentyp VARIANT.
- Legen Sie eine weitere Funktion (FC6) an und rufen Sie darin den FC5 auf.
- Legen Sie im FC6 in der Temp-Schnittstelle eine Variable (7) vom Datentyp "UDT1" an.
- Versorgen Sie die InOut-Schnittstelle des FC5 mit der Variable (7).
- Übersetzen und laden Sie die beiden Bausteine (FC5 und FC6) in Ihre CPU. Sie brauchen diese Bausteine (FC5 und FC6) nicht im Anwenderprogramm aufzurufen.
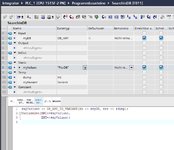
Um jetzt mit dem enthaltenen Daten zu arbeiten, kann man einfach den Variant dereferenzieren:
VariantGet(SRC:=#myVariant,
DST=>#myValues);
So holst du dir die in dem DB gespeicherten Werte und speichest sie in myVariant. Um jetzt in den Positionen einen Eintrag zu suchen und dann an eine NC oder so weiterzugeben, reicht das ja. Um direkt im PositionenDB zu arbeiten, kannst du dir eine Referenz auf den DB holen, in dem Stil:
#myReference ?= #myVariant;
#myReference^.pos2 := 0815;
Der myRefence dann im Temp der Bausteinschnittstelle deklarieren als REF_TO "PosDB"
Ich sehe bei mir jetzt im nachhinein, dass der UDT den ich angelegt habe natuerlich ein bisschen dumm gewaehlt ist, da man nicht ueber ihn iterieren kann. Also lieber ein Array of irgendwas in den UDT klatschen.
Um flexibler zu bleiben koennte man auch den UDT fuer den PositionenDB nur als Array of Byte machen. Dann liest man zuerst in ein Array of Byte aus wie zuvor auch. Danach koennte man aber mit Deserialize dieses Array of Byte einfach auf eine andere Struktur klatschen, aehnlich wie frueher Blockmove. Das vorgehen ist aber aus dem Stoff, aus dem Aufrufe von OB121 gemacht sind, also lieber vorsichtig sein. Muss AFAIK auch mit nichtoptimierten Zugriff gemacht werden, sonst passt ja beim Deserialize nichtsmehr.
Hoffe das ist jetzt das, was du eigentlich haben willst.






") .
.