-> Hier kostenlos registrieren
Guten Morgen zusammen,
wir haben hier eine Bestandsanlage, bei der ich gerade versuche (offline) zu verstehen wie ein Hubwerk im Programm funktioniert.
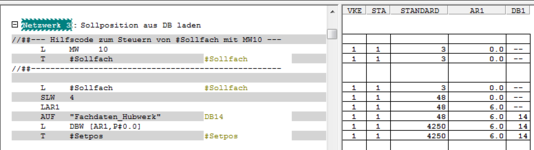
Es gibt einen FC, der Vergleicht, ob der Hubwagen (IST-Position) im Positionsfenster (Soll-Pos) ist.
Da gibt es ein NW in diesem FC, welches in AWL geschrieben wird. Ich verstehe leider nicht, was dieses NW macht. Zur Zeit kann ich nicht online an die Anlage.
Vielleicht hat jemand von euch eine Idee.
Der Code sieht wie folgt aus:
Was würde im "#Setpoint" stehen, wenn das "#Sollfach" = 0 wäre? Bzw. was macht dieser Code mit dem Sollfach?
Im DB14 sind die Sollwerte von Fach 0 bis 18 hinterlegt (jeweils als INT und jedes hat auch einen "festgeschriebenen" Anfangswert.

Schon Mal vielen Dank für eure Hilfe/ Infos.
SPS: CPU315-2 DP
SW: S7 V5.6 SP1
Grüße aus Luxembourg!
wir haben hier eine Bestandsanlage, bei der ich gerade versuche (offline) zu verstehen wie ein Hubwerk im Programm funktioniert.
Es gibt einen FC, der Vergleicht, ob der Hubwagen (IST-Position) im Positionsfenster (Soll-Pos) ist.
Da gibt es ein NW in diesem FC, welches in AWL geschrieben wird. Ich verstehe leider nicht, was dieses NW macht. Zur Zeit kann ich nicht online an die Anlage.
Vielleicht hat jemand von euch eine Idee.
Der Code sieht wie folgt aus:
Was würde im "#Setpoint" stehen, wenn das "#Sollfach" = 0 wäre? Bzw. was macht dieser Code mit dem Sollfach?
Im DB14 sind die Sollwerte von Fach 0 bis 18 hinterlegt (jeweils als INT und jedes hat auch einen "festgeschriebenen" Anfangswert.
Schon Mal vielen Dank für eure Hilfe/ Infos.
SPS: CPU315-2 DP
SW: S7 V5.6 SP1
Grüße aus Luxembourg!